The AI Compute Crisis Is Here
$600B invested, physical supply locked until 2028, and AI demand rising 10x yearly. I'm tracking what the coming compute crunch means for anyone building with AI.
OpenClaw proved AI agents actually work. 80,000+ stars. Mac Minis selling out. Developers building wild extensions overnight.
But here's what nobody's talking about: the infrastructure can't keep up.
$600 billion invested. Physical supply locked until 2028. Demand growing 10x a year.
This isn't a bubble. It's a freight train.
KB
The gap: $600 billion in, $60 billion out
The industry has poured $600-800B into AI infrastructure since 2023.
NVIDIA alone is worth $3+ trillion. Microsoft, Google, and Amazon have each committed $75-100B to data center buildouts.
The return? OpenAI made ~$3.7B in 2025. Anthropic ~$500M.
Total industry AI revenue is generously $50-70B.
That's a 10:1 ratio. Goldman Sachs asked: "Too Much Spend, Too Little Benefit?" Sequoia followed: "AI's $200B Question."
Nobody had a good answer. Now we do.
Agents don't sleep
Most analysts model AI demand around human usage patterns. That's a mistake.
You might use 50 million tokens (the units of text AI processes, roughly a word per token) a day. Then you close the laptop. You sleep.
AI agents don't sleep.
OpenClaw was a preview: autonomous systems calling other AI systems in loops, 24/7. A single agentic workflow can consume more tokens in an hour than a human uses in a month.
- One agent running 24/7: 10x to 100x a human worker's consumption
- Ten agents per team: 1,000x
- Google is already processing 1.3 quadrillion tokens per month, 130x year-over-year
Enterprise AI consumption is growing at roughly 10x annually.
Every agentic tool running in the background is a multiplier the supply chain was never built to handle.
The real bottleneck: memory, not chips
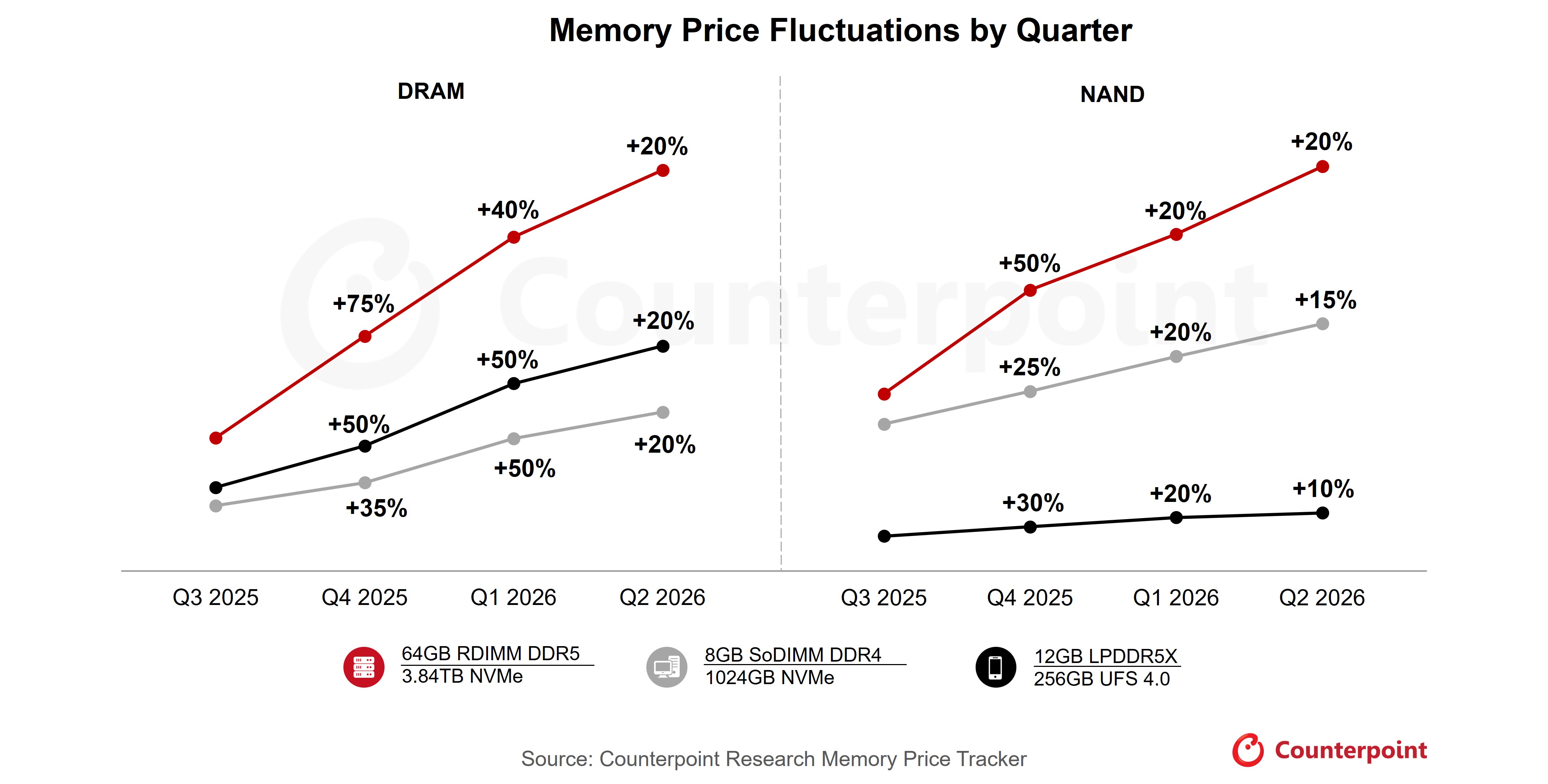
Everyone talks about GPUs. That's last year's problem. The real crisis is memory.
Running AI models depends on specialized memory chips (called HBM, or High Bandwidth Memory) that feed data to GPUs fast enough to keep up. Without enough of this memory, GPUs sit idle waiting for data.
Server memory prices rose 50% through 2025 with another 50% projected in Q1 2026.
HBM is effectively sold out. You can't buy it at any price unless you're a hyperscaler (think Google, Microsoft, Amazon).
You can't fix this fast. New fabrication plants take 3-4 years. TSMC (Taiwan Semiconductor, the company that manufactures most of the world's advanced chips) won't have its Arizona facility fully online until 2028. Intel's new capacity? 2030.
The supply isn't financially locked. It's physically constrained by the laws of construction and manufacturing.
And even if chips were abundant, data centers need 3-5 million gallons of water per day for cooling and 100-300 megawatts of power. Grid capacity is finite. Communities are blocking permits. States are capping growth.
There's nowhere to plug them in fast enough.
Your cloud provider is your competitor
AWS, Azure, and Google Cloud aren't neutral utilities. Google has Gemini. Microsoft has Copilot. Amazon is building Alexa+.
Every GPU they rent to you is one less powering their own products.
Right now, there's barely enough to go around. When the crunch hits, rate limits tighten, availability drops, and their products get the compute first.
You're renting from a landlord who's also your competitor. When resources get scarce, landlords don't sacrifice their own living room.
Meanwhile, OpenAI loses money on free users and barely breaks even on paid ones. ChatGPT Plus costs $20/month, but power users consume $15-25 in compute. The subsidies exist for market share. They can't last.
What happens next
This isn't a bubble that pops. It's a supply crisis that grinds forward.
Phase 1: Price Shock (2026-2027). Subsidies end. The cost of accessing AI services doubles or triples. ChatGPT Plus climbs to $30-40/month. Indie devs and startups get priced out first.
Phase 2: The Squeeze (2027-2028). Hyperscalers prioritize internal products. Smaller AI companies get acquired or die. Open-source models become the only alternative. New chip factories still aren't online.
Phase 3: New Capacity (2028-2029). TSMC Arizona comes online. But the landscape is already reshaped. Survivors are Big Tech, companies that secured capacity early, open-source ecosystems, and anyone who owns their compute stack. Everyone else got priced out.
This is closer to the early internet than the crypto crash. The tech is real, the valuations are insane, and the survivors become trillion-dollar companies.
The difference: you could always spin up another web server. Running AI models requires specialized hardware that takes years to manufacture.
The dot-com crash plus an oil embargo.
So what do you actually do?
Become an AI orchestrator. That's the only role that makes sense in this environment.
An orchestrator doesn't just use AI tools. They understand how compute flows, where the waste is, and how to route work intelligently across the available stack.
That's the skill set that survives a compute crunch. Not prompt engineering. Not memorizing which model is best today.
Max out your flat-rate plans before touching API pricing.
ChatGPT Pro ($200/month), Claude Max ($100/month), Gemini Ultra. These are the best deals in tech right now.
You're paying a flat rate for access to models that cost $20-50 per million tokens via API. A single heavy research session can consume $5-15 in API calls. Two sessions and you've already exceeded the monthly plan value.
Heavy users should be on every Max or Pro tier they can justify. The arbitrage window is real, but it closes as subsidies end.
Be model-agnostic by default.
Treating any single model as your permanent solution is a liability. Anthropic raises prices. You're exposed. OpenAI rate-limits your tier. You're blocked.
Building around a specific model's quirks is a trap. The goal is a routing layer: the right model for the right task, with fallbacks. Some tasks need frontier reasoning. Others just need fast, cheap token generation. Knowing the difference is the skill.
Use local open-source models when the economics make sense.
Ollama, LM Studio, and the Llama/Mistral/Qwen family have caught up fast for specific use cases: summarization, classification, code generation on known patterns, private data pipelines.
If you already have capable local hardware, running models like Llama 3 or Qwen 2.5 costs you electricity instead of API credits. That matters at scale. It also matters for data privacy. Not everything should leave your machine.
The economic logic: frontier API pricing is roughly $15-75 per million tokens on the high end. A local model running on a MacBook Pro or a cheap GPU server costs essentially nothing per token. The gap is capability, latency, and setup friction. But for a growing class of tasks, local is already good enough.
Master token efficiency.
This sounds boring until you realize it's a direct cost multiplier. Verbose prompts, redundant context, unnecessary system messages. These don't just cost more. They slow down output and burn your rate limit budget faster.
Clean context windows, structured outputs, knowing when to compress vs. when to be explicit. These compound. The developers who learn to think in tokens instead of words will have a permanent cost advantage over those who don't.
Think in pipelines, not one-shot queries.
The leverage isn't in any single model call. It's in how you chain them.
A well-designed agentic pipeline (preprocess with a cheap model, route complex sub-tasks to a capable model, summarize outputs with a fast model) can be 10x more cost-effective than throwing everything at a frontier model in a single prompt. That's orchestration. That's where the efficiency lives.
The people who build this intuition now, before the price shocks hit, will have options when everyone else is scrambling. Join if you want to track how this evolves with me.
The bottom line
AI works. The tech is transformative. But $600B invested, $60B in returns, and supply physically locked for 3 more years.
When the subsidies end, we'll either pay market rates (2-3x current costs), own our infrastructure, or get priced out.
But here's what I keep coming back to.
The compute crisis is a problem for the people building the roads, not necessarily the people driving on them. I run two production platforms as a solo engineer. I don't own a single server. I don't manage GPUs.
I plug into Vercel, Azure, Clerk, Resend, and every major AI model like Legos. The entire compute stack is composable now. You snap in what you need and ship.
While the hyperscalers fight over GPU supply and data center permits, builders with no infrastructure have a strange advantage: you can start from nothing and assemble everything.
The crisis is real. But if you're building on top of these systems instead of trying to own them, the game looks different from the inside.
Agentic & distributed systems, DeFi, and the compute economics. One email a week, no fluff.
Subscribe to the newsletter →About the author
Keenan Benning is the founder of cypher.camp, a platform that deploys AI agent teams for solo founders and small businesses. One person. Team-scale output. 60 seconds to deploy.
Other projects